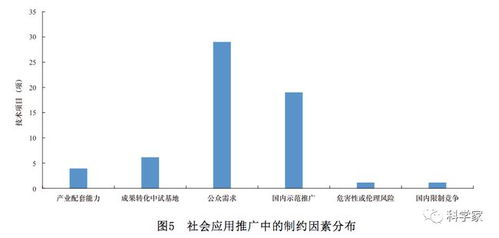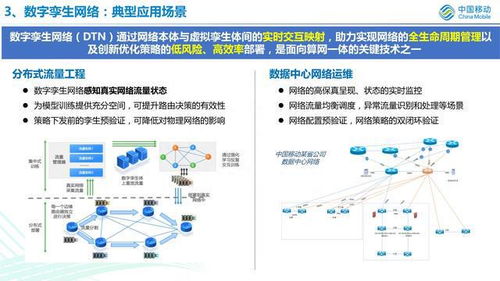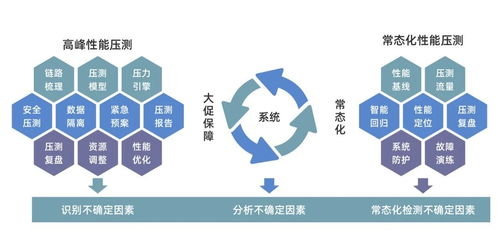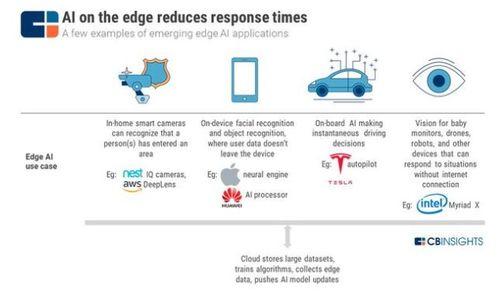
隨著第五代移動通信技術(5G)的正式商用與普及,其高速度、低延遲、廣連接的特性正從底層重塑社會生產與生活方式。它不僅是一場通信技術的升級,更是一次深刻的產業(yè)革命,對眾多行業(yè)產生顛覆性影響,并同時驅動著網絡技術開發(fā)本身進入一個全新、活躍的周期。
一、5G將深刻影響的行業(yè)領域
- 智能制造與工業(yè)互聯(lián)網:5G是工業(yè)4.0的核心使能技術。其超低延遲(可低至1毫秒)和高可靠性,使得遠程實時操控精密設備、機器視覺質檢、AR輔助維修成為可能。工廠內的海量傳感器、機器人、AGV(自動導引運輸車)將通過5G網絡無縫連接,實現生產流程的全面數字化、柔性化和智能化,構建真正的“無人工廠”或“黑燈工廠”。
- 智慧醫(yī)療:5G將極大拓展醫(yī)療服務的邊界。通過高清視頻與極低延遲,專家可進行遠程實時會診、甚至操控機械臂完成遠程手術。急救車在途中即可將患者生命體征和影像資料實時回傳醫(yī)院,實現“上車即入院”。可穿戴醫(yī)療設備的大規(guī)模連接,使得慢性病管理、老年人監(jiān)護變得更加高效和普及。
- 自動駕駛與智慧交通:5G-V2X(車與萬物互聯(lián))技術是實現高級別自動駕駛(L4/L5級)的關鍵。車輛能夠與紅綠燈、其他車輛、行人及道路基礎設施進行毫秒級信息交互,協(xié)同感知決策,大幅提升行駛安全與交通效率。智慧交通管理系統(tǒng)也將因此實現全域實時調度,緩解擁堵。
- 媒體與娛樂:超高清(4K/8K)視頻直播、VR/AR沉浸式體驗將因5G而變得流暢和普及。用戶無需下載即可瞬間加載數GB的高清內容,云游戲將成為主流,打破終端性能限制。新聞采集、賽事轉播等方式也將發(fā)生革命性變化。
- 智慧城市:5G將城市中的水、電、氣、安防、環(huán)境監(jiān)測等海量物聯(lián)網終端連接成一張統(tǒng)一的感知網絡。實現城市運行的實時監(jiān)控、精準管理和智能響應,提升公共安全、能源效率和公共服務水平。
- 農業(yè):通過部署在農田的5G傳感器網絡,可以實現對土壤、氣候、作物生長的精準監(jiān)測,并結合無人機進行自動化灌溉、施肥和噴灑,推動精準農業(yè)的發(fā)展。
二、5G對網絡技術開發(fā)帶來的機遇與挑戰(zhàn)
5G本身既是網絡技術開發(fā)的成果,也為其開辟了前所未有的新賽道。
- 網絡架構的重構與開發(fā):5G核心網采用基于云原生的SBA(服務化架構),并引入網絡切片、邊緣計算(MEC)等關鍵技術。這要求開發(fā)者深入理解云化、虛擬化、微服務、切片管理等新型網絡架構,開發(fā)能夠靈活調用網絡能力、保障切片SLA(服務等級協(xié)議)的應用和管理系統(tǒng)。
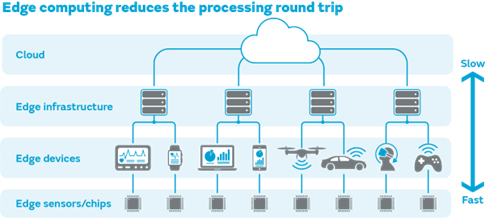
- 邊緣計算的崛起:為了滿足超低延遲需求,計算能力必須下沉到網絡邊緣。這催生了龐大的邊緣應用開發(fā)生態(tài)。開發(fā)者需要為工廠、園區(qū)、場館等邊緣場景,開發(fā)本地化的實時處理應用,如AI推理、視頻分析、工業(yè)控制軟件等,這與傳統(tǒng)的中心化云應用開發(fā)模式有顯著不同。
- 物聯(lián)網(IoT)應用開發(fā)的爆發(fā):5G mMTC(海量機器類通信)場景支持每平方公里百萬級連接,將引爆物聯(lián)網應用開發(fā)。開發(fā)者需要為智能電表、資產追蹤、智慧農業(yè)等海量終端設計低功耗、高并發(fā)的連接與管理方案,并處理由此產生的巨量數據。
- 人工智能與網絡的深度融合:5G網絡本身的運維(如流量預測、故障自愈)將深度依賴AI。5G也為AI應用提供了無處不在的高質量數據管道。開發(fā)“AI+5G”的融合應用,如基于網絡數據的智能分析平臺、自適應網絡資源配置算法等,成為重要方向。
- 安全開發(fā)面臨新挑戰(zhàn):網絡切片、邊緣節(jié)點、海量終端都引入了新的攻擊面。開發(fā)5G應用必須將安全性置于首位,需要研究并集成切片隔離、邊緣安全、輕量級終端加密等新型安全技術與協(xié)議。
- 新協(xié)議與接口的開發(fā):5G引入了大量新的服務化接口(如N1-N15)和協(xié)議,并與TSN(時間敏感網絡)等工業(yè)協(xié)議融合。理解和開發(fā)基于這些新標準與接口的軟件,是進入5G垂直行業(yè)市場的鑰匙。
總而言之,5G的到來如同一股洶涌的浪潮,正在沖刷并重塑從傳統(tǒng)制造到前沿科技的眾多行業(yè)版圖。與此它為網絡技術開發(fā)者打開了一扇通往更復雜、更關鍵、也更富創(chuàng)新空間的大門。抓住5G“網絡能力開放”和“行業(yè)應用融合”兩大核心,開發(fā)者將有機會參與到這場波瀾壯闊的數字化轉型進程中,共同塑造萬物智聯(lián)的未來。